RabbitMQ is an open-source message-broker software that originally implemented the Advanced Message Queuing Protocol (AMQP) and has since been extended with a plug-in architecture to support Streaming Text Oriented Messaging Protocol (STOMP), MQ Telemetry Transport (MQTT), and other protocols.
Written in Erlang, the RabbitMQ server is built on the Open Telecom Platform framework for clustering and failover. Client libraries to interface with the broker are available for all major programming languages. The source code is released under the Mozilla Public License.
Messaging
In RabbitMQ, messages are stored until a receiving application connects and receives a message off the queue. The client can either ack (acknowledge) the message when it receives it or when the client has completely processed the message. In either situation, once the message is acked, it’s removed from the queue.
unlike most messaging systems, the message queue in Kafka is persistent. The data sent is stored until a specified retention period has passed, either a period of time or a size limit. The message stays in the queue until the retention period/size limit is exceeded, meaning the message is not removed once it’s consumed. Instead, it can be replayed or consumed multiple times, which is a setting that can be adjusted.
Protocol
RabbitMQ supports several standardized protocols such as AMQP, MQTT, STOMP, etc, where it natively implements AMQP 0.9.1. The use of a standardized message protocol allows you to replace your RabbitMQ broker with any AMQP based broker.
Kafka uses a custom protocol, on top of TCP/IP for communication between applications and the cluster. Kafka can’t simply be removed and replaced, since its the only software implementing this protocol.
The ability of RabbitMQ to support different protocols means that it can be used in many different scenarios. The newest version of AMQP differs drastically from the officially supported release, 0.9.1. It is unlikely that RabbitMQ will deviate from AMQP 0.9.1. Version 1.0 of the protocol released on October 30, 2011 but has not gained widespread support from developers. AMQP 1.0 is available via plugin.
Pull vs Push approach
RabbitMQ is push-based, while Kafka is pull-based. With push-based systems, messages are immediately pushed to any subscribed consumer. In pull-based systems, the brokers waits for the consumer to ask for data. If a consumer is late, it can catch up later.
Routing
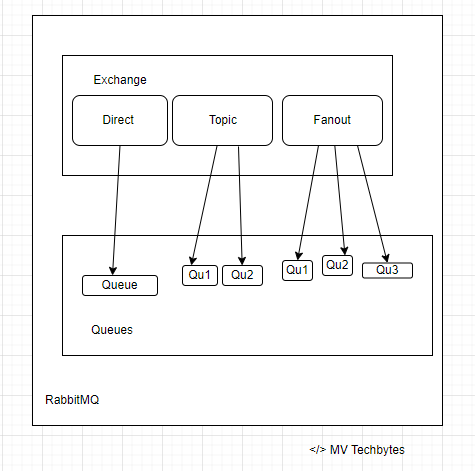
RabbitMQ’s benefits is the ability to flexibly route messages. Direct or regular expression-based routing allows messages to reach specific queues without additional code. RabbitMQ has four different routing options: direct, topic, fanout, and header exchanges. Direct exchanges route messages to all queues with an exact match for something called a routing key. The fanout exchange can broadcast a message to every queue that is bound to the exchange. The topics method is similar to direct as it uses a routing key but allows for wildcard matching along with exact matching.
Kafka does not support routing; Kafka topics are divided into partitions which contain messages in an unchangeable sequence. You can make use of consumer groups and persistent topics as a substitute for the routing in RabbitMQ, where you send all messages to one topic, but let your consumer groups subscribe from different offsets.
Message Priority
RabbitMQ supports priority queues, a queue can be set to have a range of priorities. The priority of each message can be set when it is published. Depending on the priority of the message it is placed in the appropriate priority queue. Here follows a simple example: We are running database backups every day, for our hosted database service. Thousands of backup events are added to RabbitMQ without order. A customer can also trigger a backup on demand, and if that happens, a new backup event is added to the queue, but with a higher priority.
A message cannot be sent with a priority level, nor be delivered in priority order, in Kafka. All messages in Kafka are stored and delivered in the order in which they are received regardless of how busy the consumer side is.
License
RabbitMQ was originally created by Rabbit Technologies Ltd. The project became part of Pivotal Software in May 2013. The source code for RabbitMQ is released under the Mozilla Public License. The license has never changed (as of Nov. 2019).
Kafka was originally created at LinkedIn. It was given open-source status and passed to the Apache Foundation in 2011. Apache Kafka is covered by the Apache 2.0 license.
Maturity
RabbitMQ has been in the market for a longer time than Kafka – 2007 & 2011 respectively. Both RabbitMQ and Kafka are “mature”, they both are considered to be reliable and scalable messaging systems.
Ideal use case
Kafka is ideal for big data use cases that require the best throughput, while RabbitMQ is ideal for low latency message delivery, guarantees on a per-message basis, and complex routing.
Summary
| Tool | Apache Kafka | RabbitMQ |
| Message ordering | Messages are sent to topics by message key. Provides message ordering due to its partitioning. | Not supported. |
| Message lifetime | Kafka persists messages and is a log, this is managed by specifying a retention policy | RabbitMQ is a queue, so messages are removed once they are consumed, and acknowledgment is provided. |
| Delivery Guarantees | Retains order only inside a partition. In a partition, Kafka guarantees that the whole batch of messages either fails or passes. | Atomicity is not guaranteed |
| Message priorities | Not supported | In RabbitMQ, priorities can be specified for consuming messages on basis of high and low priorities |
References
- https://www.rabbitmq.com/
- https://en.wikipedia.org/wiki/RabbitMQ
- https://www.rabbitmq.com/documentation.html