In this post, we will learn how to integrate zuul api gateway to the application developed in microservices architecture.
Our application consists of below components
- customer-service
- order-service
- eureka-server
- zuul-service
We have already seen how to create customer-service, order-service, eureka-server in the previous post given below
https://malliktalksjava.com/2020/05/28/spring-boot-netflix-eureka-integration/
Let us start integrating zuul api gateway service to the above application.
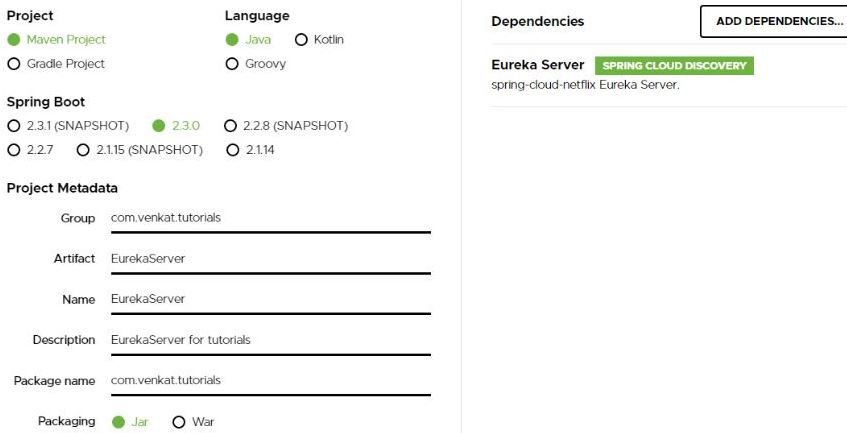
Firstly, Go to https://start.spring.io , Create SpringBoot Application with below configuration.

As shown above, Spring Web, Eureka Server, Zuul as dependencies needs to be added.
Second Step, Import the project in the Eclipse, go to application.properties and add below properties
spring.application.name=zuul-service
zuul.routes.order.url=http://localhost:8080
eureka.client.serviceUrl.defaultZone=http://localhost:8090/eureka
server.port=8079
Next step is to create following filters
- ErrorFilter
- PreFilter
- PostFilter
- RouteFilter
Below diagram depicts flow of Request & Response intercepted by Zuul filters
 Filters creation step 1: Create ErrorFilter by extending ZuulFilter and override methods and shown below
Filters creation step 1: Create ErrorFilter by extending ZuulFilter and override methods and shown below
package com.venkat.filters;
import com.netflix.zuul.ZuulFilter;
public class ErrorFilter extends ZuulFilter {
@Override
public String filterType() {
return "error";
}
@Override
public int filterOrder() {
return 0;
}
@Override
public boolean shouldFilter() {
return true;
}
@Override
public Object run() {
System.out.println(" ############# Using Error Filter ##################");
return null;
}
}
Filters creation step 2: Create PreFilter by extending ZuulFilter and override methods and shown below
package com.venkat.filters;
import javax.servlet.http.HttpServletRequest;
import com.netflix.zuul.ZuulFilter;
import com.netflix.zuul.context.RequestContext;
public class PreFilter extends ZuulFilter {
@Override
public String filterType() {
return "pre";
}
@Override
public int filterOrder() {
return 0;
}
@Override
public boolean shouldFilter() {
return true;
}
@Override
public Object run() {
RequestContext ctx = RequestContext.getCurrentContext();
HttpServletRequest request = ctx.getRequest();
System.out.println(" ############# In Pre Filter ################## ");
System.out.println(
"Request Method : " + request.getMethod() + " Request URL : " + request.getRequestURL().toString());
return null;
}
}
Filters creation step 3: Create PostFilter by extending ZuulFilter and override methods and shown below
package com.venkat.filters;
import java.io.IOException;
import java.io.InputStreamReader;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import com.google.common.io.CharStreams;
import com.netflix.zuul.ZuulFilter;
import com.netflix.zuul.context.RequestContext;
public class PostFilter extends ZuulFilter {
@Override
public String filterType() {
return "post";
}
@Override
public int filterOrder() {
return 0;
}
@Override
public boolean shouldFilter() {
return true;
}
@Override
public Object run() {
RequestContext ctx = RequestContext.getCurrentContext();
System.out.println(" ############# In Post Filter ################## ");
try {
System.out.println(
"Response Status Code : " + ctx.getResponseStatusCode() + " Response Body : " + CharStreams.toString(new InputStreamReader(ctx.getResponseDataStream(), "UTF-8")));
} catch (IOException e) {
}
return null;
}
}
Filters creation step 4: Create RouteFilter by extending ZuulFilter and override methods and shown below
package com.venkat.filters;
import com.netflix.zuul.ZuulFilter;
public class RouteFilter extends ZuulFilter {
@Override
public String filterType() {
return "route";
}
@Override
public int filterOrder() {
return 0;
}
@Override
public boolean shouldFilter() {
return true;
}
@Override
public Object run() {
System.out.println("Using Route Filter");
return null;
}
}
Next, Add @EnableZuulProxy to ZuulProxyApplication class in zuul-service and add bean configurations for Filters which we have created as shown below
package com.venkat;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.netflix.eureka.EnableEurekaClient;
import org.springframework.cloud.netflix.zuul.EnableZuulProxy;
import org.springframework.context.annotation.Bean;
@SpringBootApplication
@EnableEurekaClient
@EnableZuulProxy
public class ZuulProxyApplication {
public static void main(String[] args) {
SpringApplication.run(ZuulProxyApplication.class, args);
}
@Bean
public PreFilter preFilter() {
return new PreFilter();
}
@Bean
public PostFilter postFilter() {
return new PostFilter();
}
@Bean
public ErrorFilter errorFilter() {
return new ErrorFilter();
}
@Bean
public RouteFilter routeFilter() {
return new RouteFilter();
}
}
Once we are done creating all the filters package structure of our
zuul-service will be as shown as shown below

Now we will see changes to done to the customer-service application to enable requests
pass via zuul-service filters.
Go to CusomerControllerClient.java in customer-service replace
List<ServiceInstance> instances = discoveryClient.getInstances("ORDER-SERVICE");
with
List<ServiceInstance> instances = discoveryClient.getInstances("ZUUL-SERVICE");
and
String completeURL = baseURL + "/customerorder";
with
String completeURL = baseURL + "/order/customerorder";
Upon completion of all the code changes/additons discussed above run all the services, eureka-server, order-service, customer-service, zuul-service.
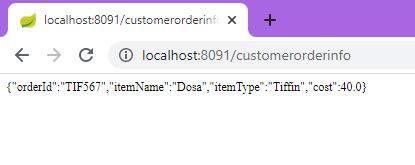
Following will be output once we hit the REST endpoint /customerorderinfo
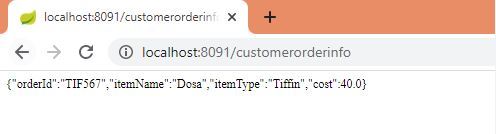
zuul-service logs on hitting the REST end point are given below, clearly we can see both Request and Response pass through Pre, Route, Post Filters
############# In Pre Filter ##################
Request Method : GET Request URL : http://Dell:8079/order/customerorder
Using Route Filter
############# In Post Filter ##################
Response Status Code : 200 Response Body : {"orderId":"TIF567","itemName":"Dosa","itemType":"Tiffin","cost":40.0}
2020-05-31 18:56:18.494 INFO 3892 --- [trap-executor-0] c.n.d.s.r.aws.ConfigClusterResolver : Resolving eureka endpoints via configuration
############# In Pre Filter ##################
Request Method : GET Request URL : http://Dell:8079/order/customerorder
Using Route Filter
############# In Post Filter ##################
Response Status Code : 200 Response Body : {"orderId":"TIF567","itemName":"Dosa","itemType":"Tiffin","cost":40.0}
Conclusion
In this post, we have seen how to configure Zuul-proxy and make requests from one microservice pass through customized zuul filters. These filters enable us to apply functionality to our edge service. These filters help us perform the following functions:
- Authentication & Security – identifying authentication requirements for each resource and rejecting requests that do not satisfy them.
- Monitoring – tracking data and statistics at the edge which gives us a view of production.
- Dynamic Routing – dynamically routing requests to various back-end clusters.
- Load Shedding – allocating capacity for each type of request and dropping requests that exceeds the limit set.
- Stress Testing – increasing the traffic to a cluster to measure its performance.
- Static Response handling – sending some responses directly at the edge instead of forwarding them to an internal cluster.
Related links:
References: